Optimization Basis
Training AI and machine learning models reduces to solving an optimization problem:
where
where
The main challenge arises from the scale: modern deep learning involves billions of parameters and data points, making this a very expensive large scale optimization problem. The choice of optimizer directly affects the model’s final accuracy, training speed, and cost.
Gradient Descent
Gradient descent updates the parameters by moving in the direction opposite to the gradient of the loss:
where we start from an initialization
The learning rate
Mini-batch Gradient Descent
For large datasets, the loss function in Eq. equ:lossform requires summing over many data points. Correspondingly, in gradient descent, computing the gradient involves evaluating the full sum:
Mini-batch gradient descent approximates this full-batch gradient by averaging over a smaller subset of data:
where
An extreme case is when a single data point is used:
where
Using mini-batches introduces variance and noise in the gradient estimates. However, it significantly reduces computational cost per update and enables more frequent updates. In practice, it is often more effective to take many noisy steps than to compute a single precise but expensive update.
Momentum
In gradient descent, gradients can vary significantly across iterations; that is, the gradients
Momentum is a technique used to smooth the gradient across iterations. Instead of directly using the current gradient to update the parameters, momentum computes an exponentially weighted moving average of past gradients:
Unrolling the recurrence shows that
Typically,
The main benefit of momentum is that it smooths out noise, encourages consistent update directions, and reduces oscillations. This often leads to faster and more stable convergence.
In fact, in the limit of a small step size, momentum corresponds to the physical dynamics of a ball moving in a potential field with friction. The momentum term captures the effect of inertia in this analogy.
Remark 2.1.Recall that
Therefore,
is a convex combination of as shown in Eq. equ:mtgt.
Nesterov Momentum
If
With a proper choice of
Adaptive Methods
Coordinate Imbalance
In neural network training, different parameters can have vastly different gradient scales; that is, the magnitudes of the elements in the gradient vector
Signed Gradient
Signed methods address coordinate imbalance by applying the sign function to the gradient or momentum vector, equalizing the update magnitude across coordinates:
This is one of the most aggressive normalization approaches, as it forces all coordinates to have equal update magnitude. Consequently, the update depends only on the sign of the gradient or momentum, not its magnitude.
As a trade-off, smoother normalizations can be used, such as a soft variant of the sign function:
where
with
Adam Optimizer
The Adam optimizer (short for adaptive moment estimation) combines momentum with adaptive scaling. A simplified version of Adam’s update rule is:
where
Note that when
Adam can also be interpreted as applying an adaptive scaling factor to softsign momentum:
The adaptive learning rate
Bias Correction of Adam
Standard Adam implementation is slightly more complicate than what we wrote above:
Here, we introduce
To see why we may (or may not) need to introduce bias correction, consider the case where
Using the identity
This shows that
However, if we initialize
Remark 2.2.Hence, the need for this correction term is directly tied to initializing the momentum with
, . In practice, the bias correction becomes less important as
increases, since as .
Regularization and Weight Decay
The Overfitting Problem
Large neural networks can memorize training data instead of learning generalizable patterns. This leads to excellent training performance but poor validation performance. Regularization is a standard technique to mitigate overfitting by discouraging overly complex models.
L2 Regularization and Weight Decay
L2 regularization is one of the most commonly used techniques. It is also known as ridge regression in the context of least squares. It adds a penalty term to the loss function:
Applying gradient descent to this objective yields:
The term
It shrinks the parameters toward zero, encouraging smoother models that tend to generalize better.
AdamW
For adaptive optimizers like Adam, weight decay should be applied separately from the gradient update. This is implemented in the AdamW variant:
where
Note, however, that this is no longer equivalent to minimizing an L2-regularized objective.
This decoupled approach ensures consistent regularization across parameters and often leads to improved generalization performance.
Muon Optimizer
Adam normalizes updates coordinate by coordinate. Muon takes a different view: many important neural network parameters are matrices, such as the weight matrix of a hidden linear layer. Instead of only balancing individual coordinates, Muon tries to balance the update as a matrix.
The name Muon stands for MomentUm Orthogonalized by Newton-Schulz. A simplified version of the update is:
where
If
The practical benefit is efficiency. In recent language model training experiments, Muon often reaches the same validation loss with fewer tokens or fewer training steps than AdamW. Its per-step update can be slightly more expensive than AdamW, but the improved sample efficiency can still reduce the overall training cost. This is why Muon has become interesting for modern LLM pretraining, where optimizer efficiency directly translates into saved GPU time.
The figure is a toy two-dimensional illustration. It treats the two plotted directions as a proxy for singular directions: momentum smooths the update, Adam rescales coordinates, and Muon-like orthogonalization flattens the update scale before applying the step.
In practice, Muon is mainly used for hidden two-dimensional weight matrices. Other parameters, such as embeddings, output heads, biases, gains, and scalar or vector parameters, are usually optimized with AdamW.
Neural Networks
A central goal in machine learning is function approximation: to learn an unknown function
We typically adopt a parametric approximation framework. This means that rather than searching over all possible functions
Here, the parameter vector
The learning problem is then formulated as an optimization task: find the parameter configuration that minimizes the expected loss between the predictions and the ground truth:
In this expression, the loss function
This formulation highlights the interplay between three key elements: the choice of function class (the architecture of the neural network), the loss function that reflects the task objective, and the optimization procedure used to adjust
From Linear to Nonlinear: Building Neural Networks
The simplest parametric model is the linear function:
This model is attractive for its simplicity and efficiency. Linear models can be trained efficiently, often with closed-form solutions in regression settings, and they provide clear interpretability: each coefficient
However, despite these advantages, linear models have limited expressivity. They can only capture relationships that are linear in the input space, meaning they are fundamentally incapable of representing curved decision boundaries or complex nonlinear structures. This limitation makes them insufficient for most modern machine learning tasks, such as image recognition or natural language processing, where data exhibits intricate nonlinear dependencies.
To overcome this limitation, we introduce neural networks, which generalize linear models by combining linear transformations with nonlinear activation functions. A single-layer neural network, also known as a shallow network, can be expressed as
where
The introduction of nonlinearity is the key to increasing expressivity. Without
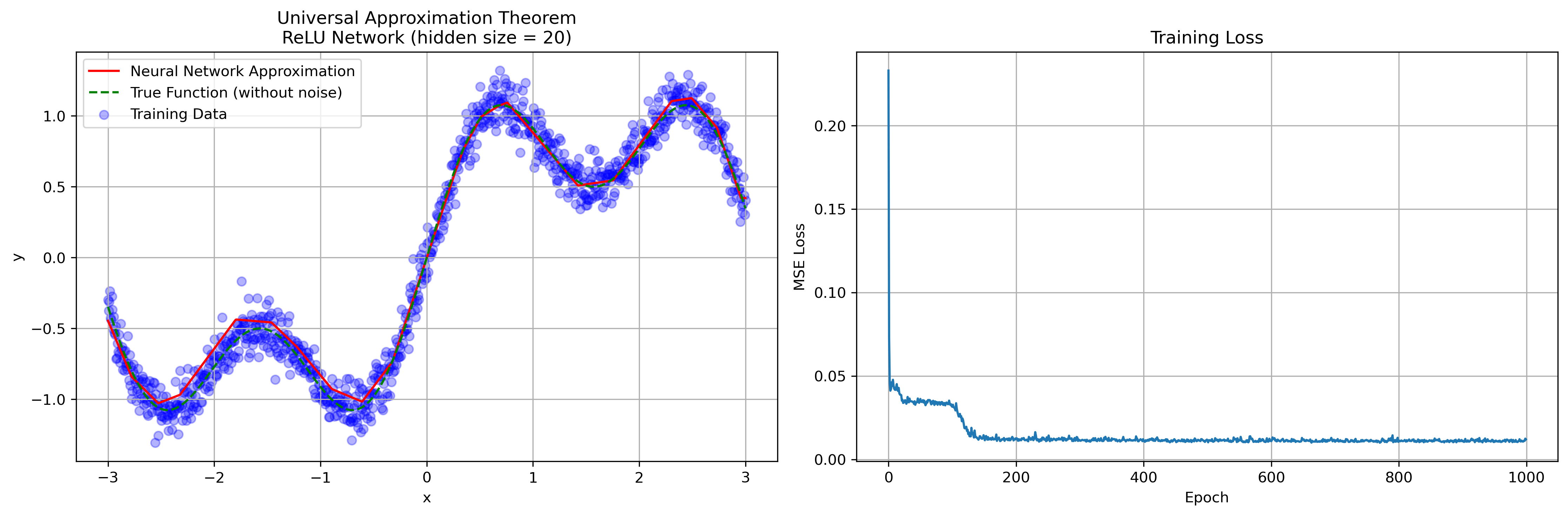
In this way, neural networks can be seen as building blocks: each layer transforms the input into a new representation, with nonlinearities ensuring that successive layers capture progressively richer patterns. This simple extension beyond linear models forms the foundation of deep learning.
The figure shows a one-dimensional target function
Universal Approximation Theorem
Theorem 2.1.A neural network with a single hidden layer can approximate any bounded continuous function
on a bounded domain to arbitrary accuracy, provided it has sufficiently many neurons: More precisely, if
is continuous and not a polynomial, then for any there exists and parameters such that
Assumptions and scope.
The statement is uniform approximation on compact sets: boundedness of
Proof sketch (ReLU case).
-
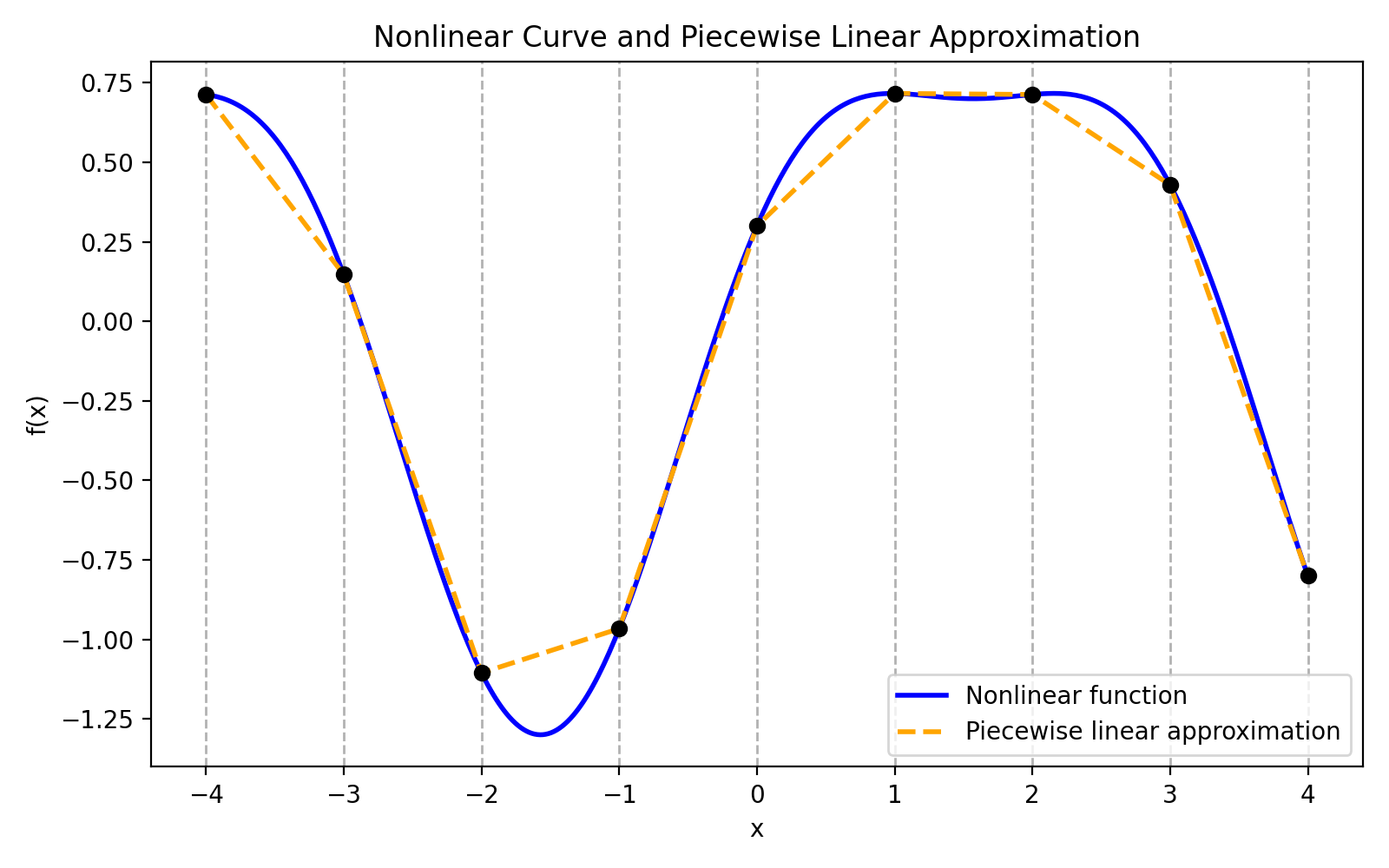
Piecewise-linear reduction. Since
is continuous on compact , for any there exists a piecewise-linear (PL) function such that (e.g., by triangulating and linearly interpolating nodal values). -
ReLU realizes PL functions. In one dimension, a ReLU atom
creates a kink at . Finite differences of shifted ReLUs synthesize hat/bump functions, e.g.,
which is triangular on
Intuition.
Each neuron implements an affine projection followed by a nonlinearity, introducing a kink (ReLU) or a smooth bump (sigmoid/
Why not polynomial?
If
What the theorem does not say.
It does not provide approximation rates in terms of smoothness of
Depth vs. width.
While the theorem uses a single hidden layer (width-driven expressivity), increased depth can represent certain function families with exponentially fewer neurons. Thus, depth trades width for hierarchical composition, often yielding superior parameter efficiency in practice, even though universality already holds at depth
Deep Neural Networks: Composition of Functions
Instead of wide single-layer networks, we can build deep architectures by stacking multiple layers together:
Here, each layer
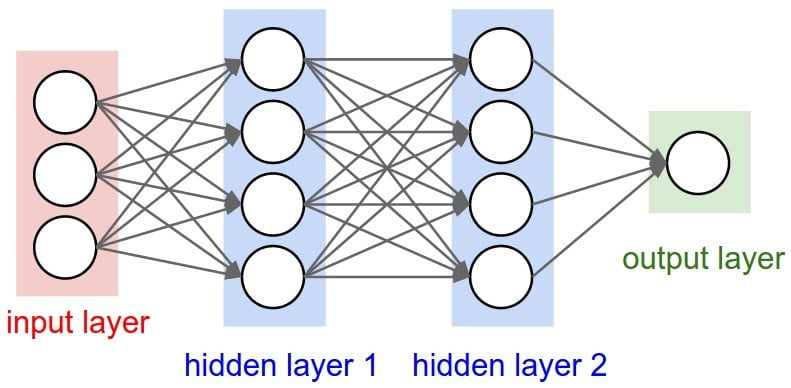
The key distinction between shallow and deep models lies not in their theoretical ability to approximate functions (both can be universal approximators), but in the efficiency and structure of that approximation. Depth introduces a hierarchy that allows complex functions to be expressed more compactly.
Pros of Depth
-
Composition matches the data. Real signals are built in layers: pixels become edges, edges become parts, parts become objects; tokens become phrases, phrases become meaning. Depth gives the model the same kind of compositional workspace.
-
More expression per parameter. A shallow network can approximate many functions, but it may need enormous width. A deep network can reuse intermediate features, so small transformations can combine into a very rich function.
-
Better inductive bias. Depth encourages progressively more abstract features. When the task has structure, this often helps the model generalize instead of memorizing every pattern separately.
Cons of Depth
-
Harder optimization. Every extra layer is another transformation that gradients must cross. Without good initialization, normalization, and residual paths, signals can vanish, explode, or become noisy.
-
Depth is not automatically useful. Adding layers only helps if they learn useful refinements. A poorly designed deeper model can train worse than a shallower one.
-
More compute and fragility. Deeper models usually cost more memory, more latency, and more tuning. Architecture details start to matter a lot.
Colab Python Notebook
Residual Connections (ResNet)
The key idea of ResNet is to make each block learn a correction to a pass-through signal, rather than learning the whole transformation from scratch. If the desired mapping is
so the block computes
If the input and output dimensions do not match, the shortcut is projected instead:

This changes the optimization problem. If an extra block is not useful, it can make
In classic ResNets,
The practical lesson is that depth works best when each layer only needs to make a useful refinement. Residual blocks preserve an easy path for information and gradients, let layers start near identity, and make very deep networks trainable without asking every block to reinvent the representation.
Attention Mechanism
Modern architectures introduce the attention mechanism. Given a query vector
where the weights are obtained by a softmax over similarity scores
Here
From a matrix viewpoint, if we stack queries into
In the figure, click a token to make it the query. The token row shows where attention flows, the heatmap shows the softmax weights formed from
Self-Attention and Multi-Head Attention
Multi-Head Attention
Attention can be extended with multiple heads to allow the model to focus on complementary relational patterns:
where each head has its own
Self-Attention
In self-attention, every element serves simultaneously as a query and as a reference:
Each position
Properties.
-
Permutation structure. As a set operation, self-attention is permutation equivariant to the order of inputs; it becomes order-aware once position information is injected (see below). Global pooling of self-attention outputs yields permutation invariance.
-
Long-range dependencies. Every token can directly attend to any other token in one layer, providing a content-adaptive receptive field.
-
Rich information exchange. Attention weights form data-driven routing of information across elements, allowing the model to emphasize salient interactions while suppressing irrelevant ones.