Language Models
- Languages are discrete-valued sequences:
where
- Discrete valued
- Variable length
- Sequential in nature
- How to build generative models for such data?
Auto-regressive Language Models
- It is natural to expand the probability using chain rule:
- This allows for
- Maximum likelihood estimation during training
- Maximizing the log likelihood of the training data
- Maximum likelihood estimation during training
-
Next token prediction during inference
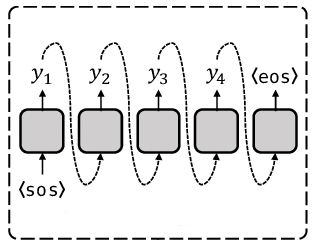
-
Universal question answering:
Neural Parameterization of Auto-regressive Models
- Chain rule:
- All
are modeled with a neural network with a softmax head:
where
Generative Pre-trained Transformers (GPT)
: Taken to be a transformer with causal masks.
- Key: All logits in a sentence can be calculated in parallel during training.
flowchart LR Tokens["tokens w1 ... wn"] --> Embed["token + position embeddings"] Embed --> Blocks["causal GPT blocks"] Blocks --> Head["linear head"] Head --> Logits["logits for all positions"]
Transformer-Based Language Models
Language models apply self-attention to sequences of tokens. Consider the sentence
We index tokens as
The resulting sequence
Position embeddings supply order information that self-attention alone does not encode. In autoregressive models, a causal mask guarantees that token
More Details on Transformer-Based LMs
-
Token-wise MLPs. The MLP layers act independently on each token’s hidden state (shared parameters across positions), providing nonlinear mixing of channel dimensions complementary to the cross-token mixing of attention.
-
Residual connections. Additive shortcuts are used throughout the stack to preserve gradient flow and allow layers to learn residual refinements of the representation.
-
Layer normalization. Normalization stabilizes optimization by reducing covariate shift within layers:
with trainable scale
and bias . It is applied at fixed points of the block (before/after sublayers) to keep activations in a favorable range. -
Positional encodings. A common choice is sinusoidal position embeddings,
which provide a deterministic, smooth encoding of order and relative offsets. (Other encodings are possible; here we focus on the sinusoidal case for clarity.)
-
Input composition. Inputs are typically the sum of word and position embeddings rather than their concatenation, keeping the model width fixed while allowing both content and order information to coexist in each token vector.
-
Causal masking. In autoregressive LMs (e.g., GPT-style), a strictly triangular attention mask enforces that token
cannot attend to positions , ensuring the factorization needed for left-to-right likelihood and generation.
Overall, the attention mechanism provides content-adaptive aggregation; multi-head attention diversifies this aggregation across subspaces; self-attention enables all-to-all interaction within a layer; and positional information plus masking specialize the same machinery to the sequential constraints of language modeling. Together with residual connections, layer normalization, and token-wise MLPs, these components form the core computational pattern of Transformer-based LMs.