Rectified Flow
Our goal is to learn a transport mapping
We now discuss an alternative approach, in which
Remark 6.1.We distinguish two broad types of generative models:
- One-step models. The mapping
is specified directly by a neural network, as in normalizing flows, GANs, and autoencoder-based models. - Process models. The mapping is obtained by simulating an iterative or continuous-time process whose local updates are parameterized by a neural network, as in diffusion (SDE), flow (ODE), and autoregressive models.
In particular, in ODE (“flow”) generative models, we train a continuous-time process to gradually transform noise
where the velocity field
Integrating the ODE defines a mapping
Numerical Simulation of ODEs
Once the velocity field
with step size
Backward Integration and Inversion
Since the ODE admits a unique solution for each initial condition, the mapping
Starting from a sample at
Maximum Likelihood Training of Neural ODEs
To understand how Neural ODEs can be trained by maximum likelihood, we consider the evolution of probability densities along the continuous flow induced by the ODE. Let
up to time
A key property of continuous-time flows is that the log-likelihood
This relation shows how the likelihood of a data point evolves as it is transported backward along the flow from time
Maximum Likelihood Estimation
Given the expression above, one can in principle train the Neural ODE by maximum likelihood. For data sampled from the empirical distribution
where
Practical Challenges
Although conceptually elegant, maximum likelihood training of Neural ODEs is computationally demanding. Each evaluation of the log-likelihood requires solving an ODE trajectory, and backpropagation involves differentiating again through this ODE solution. As a result, both forward and backward passes are significantly more expensive than in discrete normalizing flows.
Another limitation is that the optimal velocity field is not unique: many different flows can transport the base distribution to the same target distribution with equal likelihood. This non-uniqueness complicates optimization and can lead to training instabilities in practice.
Rectified Flow: A Simpler and Better Approach
Although Neural ODEs can be trained using maximum likelihood, the approach is computationally heavy and difficult to optimize. It took several years of research to realize that there exists a much simpler and often better approach---one that is essentially simulation-free and avoids solving ODEs during training.
This insight first emerged from the study of diffusion generative models. Denoising diffusion probabilistic models (DDPMs) revealed that stochastic differential equation models could be trained by directly matching denoising behavior, and later developments such as denoising diffusion implicit models (DDIMs) demonstrated that these stochastic processes could be associated with deterministic ODEs. Similarly, score-based generative models were shown to correspond to a deterministic probability flow ODE, offering a new route to generative modeling without explicit simulation of stochastic dynamics.
These ideas were soon simplified and generalized into a family of formulations, including rectified flow, flow matching, and stochastic interpolants. All of these frameworks share the same principle: instead of learning an ODE by maximizing likelihood, one directly learns a velocity field that transports data and noise along simple, analytically chosen reference paths.
Rectified Flow
To build intuition, consider the simplest case of transporting a single data point
What is the most natural ODE that moves
to ?
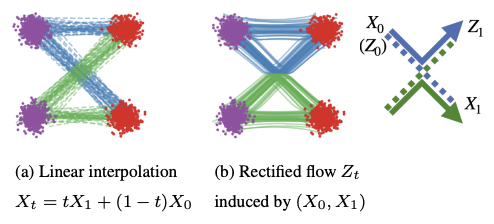
A natural choice is to use straight-line paths connecting noise and data. This geometric intuition leads to the so-called straight interpolation,
which traces the shortest path between the starting point
To derive the corresponding ODE, we differentiate the interpolation:
Since the ODE must be expressed in terms of the current state
This identifies the ideal velocity field for straight-line transport:
The scaling factor
Rectified Flow: Straight-Path Dynamics
For a single data point
we can compute its time derivative and obtain the ideal dynamics
This ODE exactly reproduces the straight path for every
An appealing property of straight-line dynamics is that their numerical discretization is extremely simple. A single forward Euler update,
recovers the exact endpoint of the continuous path. Thus, the trajectories are not only perfectly straight but also exactly realizable with a one-step discretization.
To learn such dynamics with a neural network, we introduce a parametric velocity field
This leads to the objective
which, after substituting
with
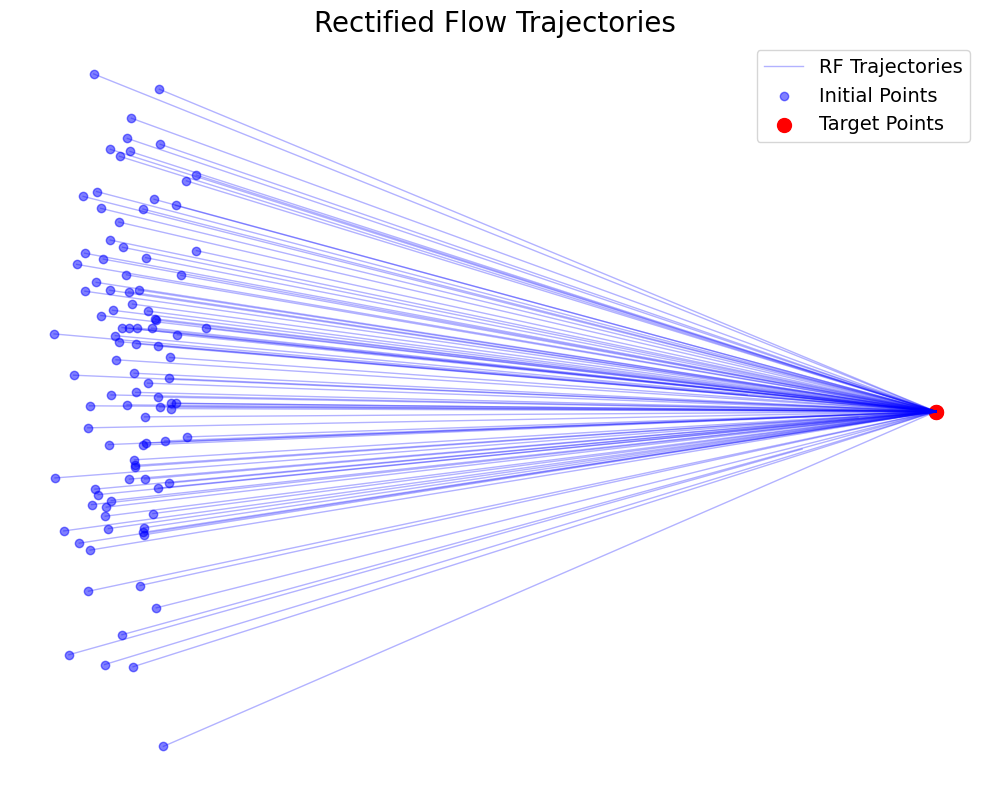
Rectified Flow with Multiple Data Points
The single-point case suggests a clean formulation of straight-path dynamics, but real data consist of many points. To understand how rectified flow generalizes, consider several data—noise pairs simultaneously. Suppose we draw two independent pairs
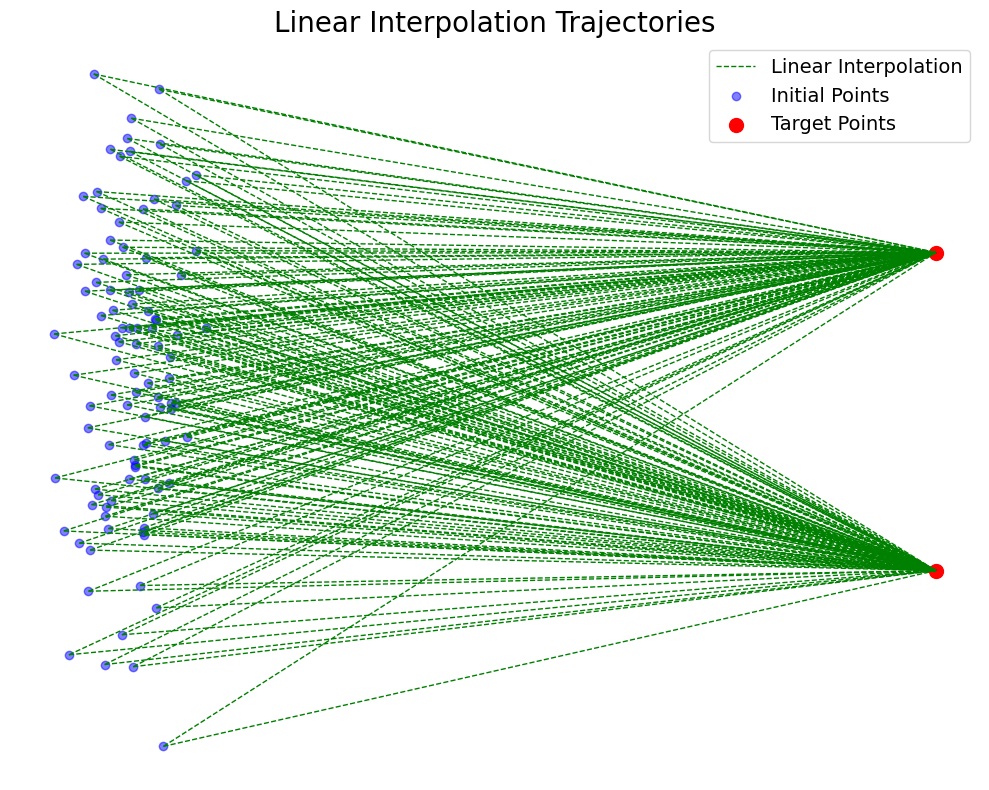
 A difficulty appears immediately: straight-line interpolations from different data—noise pairs may intersect. That is, for some time
A difficulty appears immediately: straight-line interpolations from different data—noise pairs may intersect. That is, for some time
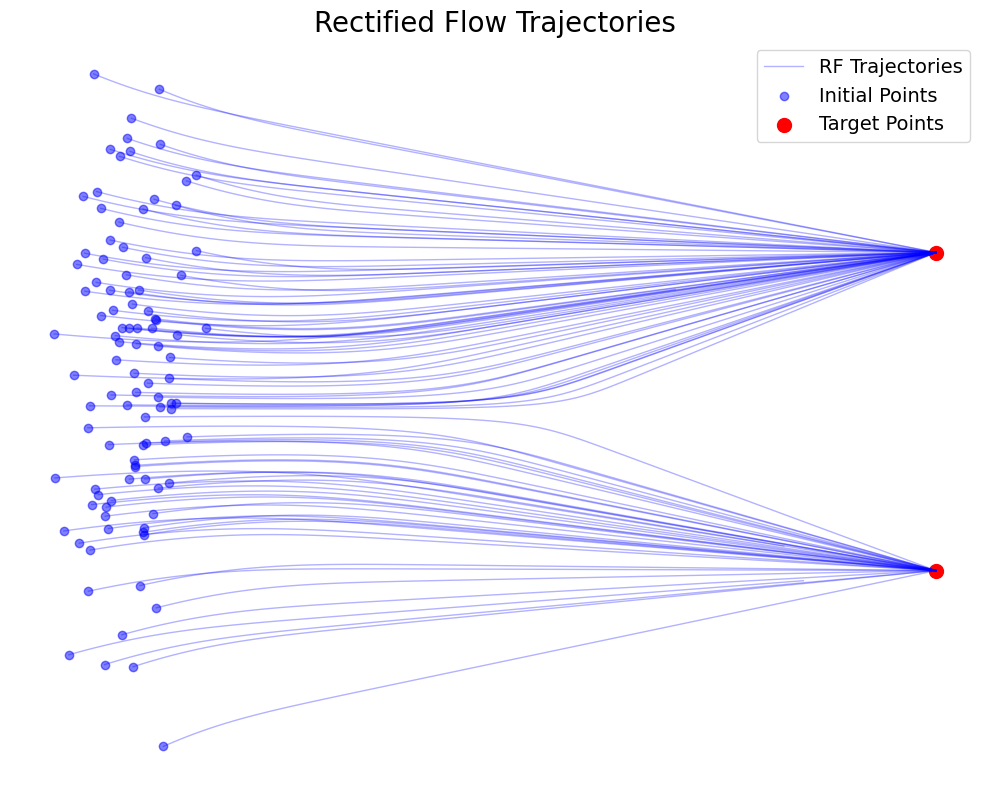
However, intersections of this form are impossible for the trajectories of an ODE. If a point
This raises the key question:
Can we convert linear interpolation into a valid ODE flow that respects the non-intersection property?
The resolution is surprisingly simple. Whenever trajectories intersect, we assign them a common direction by taking the conditional expectation of the ideal velocity at that point. Formally, we define the ideal velocity field as
where the expectation is over all data—noise pairs that interpolate to the same location
To estimate this conditional expectation in practice, we again use a regression loss. Sampling independent pairs
This loss has a natural statistical interpretation. For any pair of random variables
Rectified Flow Loss and Training Procedure
The rectified flow objective follows directly from the conditional expectation characterization derived earlier. Given independent draws
we define the rectified flow loss as
This regression loss trains the neural velocity field
In practice, the integral and expectations are optimized using stochastic gradient descent. Each iteration draws a minibatch of samples
and forms the interpolated points
The instantaneous training loss for each sample is then computed as
and the parameters
After training, the learned velocity field defines a generative model. Starting from a noise sample
transporting the initial noise toward the data distribution. The solution at time
Theoretical Properties of Rectified Flow
To analyze the behavior of rectified flow, consider independent noise—data pairs
This linear path defines a simple time-indexed random process
Rectified flow, on the other hand, induces a second process
where the ideal velocity field is
This velocity field takes the average direction of all straight-line interpolations passing through any given point
Although the interpolation process
meaning that they share the same marginal distribution at every time. This agreement of marginals is a fundamental feature that enables rectified flow to match the data distribution while maintaining ODE-consistent dynamics.
Theorem 6.1.Let
denote the marginal density of either process or . Then satisfies the continuity equation Here the divergence of a vector field
is If the continuity equation admits a unique solution for the given initial density
, then both processes must share the same marginal distribution at all times. Thus, the rectified flow ODE and the linear interpolation induce the same family of marginals .
Proof of the Continuity Equation
To derive the continuity equation satisfied by the marginal densities
This expresses the time derivative of the expectation in terms of the time derivative of the density.
We now compute the same derivative in a second way, using the dynamics of the process
Using the tower property of conditional expectation,
Since
By definition of the ideal velocity,
we obtain
Finally, we apply integration by parts:
assuming that
Since this equality holds for all test functions
We have used the standard integration-by-parts identity
valid for smooth
Rectified Flow: ODE Generative Model
- Rectified Flow: Learning ODE generative models from interpolations
- Draw batches of samples:
- Construct interpolation between noise and data:
- Minimize the loss function:
- After training, generate new data by solving the ODE:
ODE vs. SDE Models
- ODE (Flow): Generate data
by solving
- SDE (Diffusion): Generate data
by solving
where
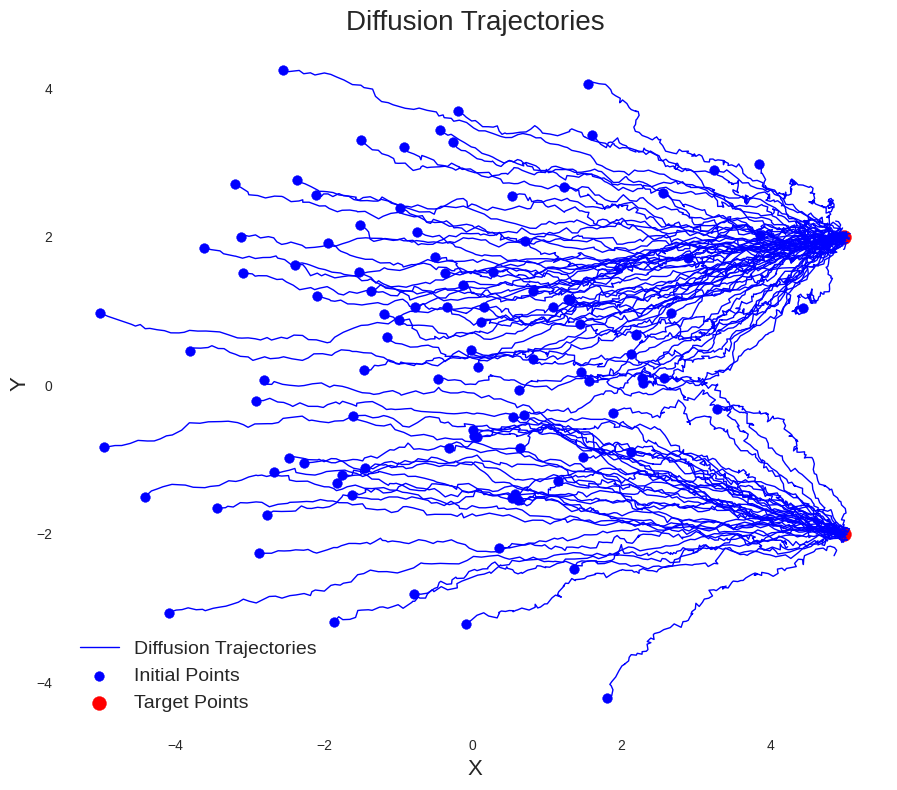
- SDE vs. ODE: How and Why?
Rectified Flow Recap
- Assume we have trained a rectified flow ODE model:
- Marginal preserving property: At each time
, the distribution of matches the distribution of the interpolation
Thus,
- However, in practice, we cannot perfectly simulate the ODE due to model and numerical error.
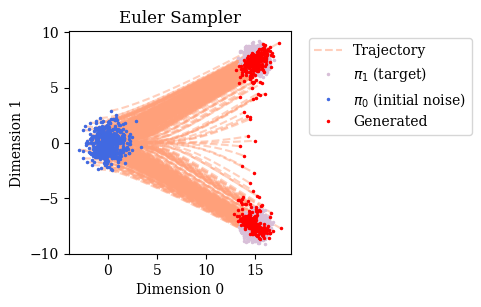
Diffusion = ODE + Langevin
- If we know
, we can correct errors using Langevin dynamics:
(Here,
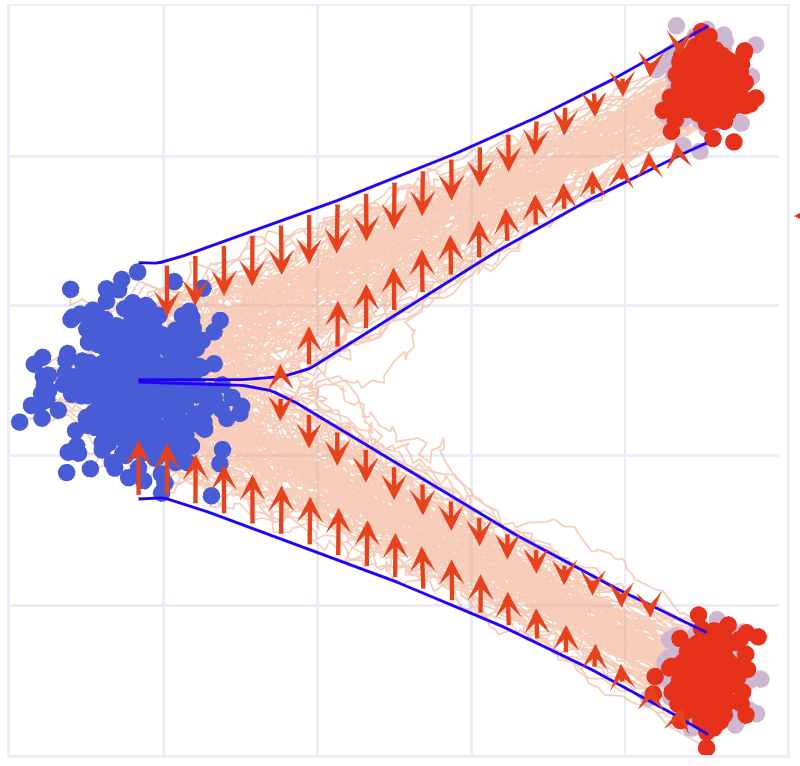
- Combine ODE and Langevin dynamics directly:

- Key: For Gaussian noise, the score function
is directly related to :
Tweedie’s Formula
At time
Then, Tweedie’s formula gives:
Proof
Proof. Given
, we have , thus Since
, we have Taking the gradient:
Recognizing the conditional expectation, we get:
◻
- On the other hand, the RF velocity is:
Thus,