Generative Adversarial Networks (GANs)
Given a dataset
produces samples that closely approximate
If the density function
Generative Adversarial Networks (GANs).
An alternative approach is to give up the architectural constraint that the transformation
To train such models, we must resort to likelihood-free approaches to estimate
Likelihood-Free Training via Moment Matching
Given a generative model
The goal is to find parameters
How can we tell if two datasets follow the same distribution? This is a classical two-sample testing problem in statistics. The idea is to compare various empirical statistics (or “moments”) of the two datasets.
For example, we can match the sample means:
However, matching only the mean is clearly insufficient. We can extend this idea by also matching higher-order moments, such as the variance. In the one-dimensional case, this corresponds to matching the second order moment:
This is, of course, still not sufficient unless the data distribution is Gaussian. To ensure that two general distributions match perfectly, we would ideally want to match all possible statistics, such as, all polynomial moments.
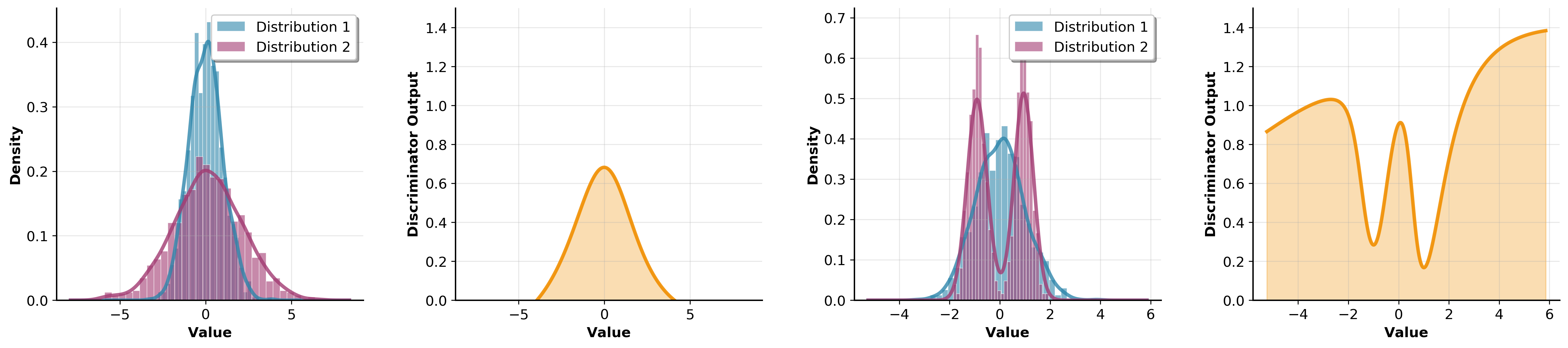
This idea can be generalized by requiring that the generated distribution
Here, the function class
Definition 4.1.A set of functions
is called discriminative if it is rich enough such that matching the expectations over all implies equality of the distributions:
Example 4.1.For distributions defined on
, we have where the choice of the function class
determines which moments are being matched. Several important examples include: Bounded Continuous Functions
Matching expectations for all bounded continuous functions guarantees equality of the two distributions.
Polynomials
If all polynomial moments agree, the two distributions coincide (under suitable regularity conditions).
Moment Generating Functions
Equality of moment generating functions implies that the distributions are identical.
Single-Neuron Neural Network
Here,
is a nonlinear activation function, such as .
In practice, we may choose the test function class
Integral Probability Metrics (IPM)
Based on the moment matching idea introduced above, we can define a notion of discrepancy between the model distribution
This family of divergences is known as the integral probability metric (IPM).
When
This simplification holds because, for any function
In other words, the symmetry of
Remark 4.1.The supremum in the IPM definition can diverge if the test function
is allowed to grow arbitrarily large or oscillate too rapidly. For instance, if with an unrestricted constant , then which can be made arbitrarily large by increasing
. Constraining (e.g., ) prevents this divergence. Hence,
must impose a constraint on the norm, magnitude, or smoothness of , such as equiring or ; see Table tab:ipm. Such constraints limit the “strength” of, ensuring that the IPM measures genuine distributional differences rather than the effect of scaling. Name Equivalent Formulation / Comment Total variation (TV) Maximum mean discrepancy (MMD) RKHS norm induced by a kernel Wasserstein-1 distance Kantorovich—Rubinstein dual form
: Examples of integral probability metrics (IPMs). Examples of integral probability metrics (IPMs). By choosing different function classes
Regularized IPM
In practice, it is common to add
Generative Adversarial Networks (GANs)
In practice, one often considers a parametric critic
where we introduce a regularization term in which
Training the generator then becomes a minimax problem:
This formulation captures the essence of adversarial training, in which two components (the generator and the critic) interact in a competitive optimization process:
-
Critic (or Discriminator)
: Given the current generator , the critic seeks to find a test function that maximizes the discrepancy between the real and generated data distributions. Intuitively, the critic tries to distinguish real samples from fake ones by assigning higher scores to and lower scores to . The regularization term limits the critic’s expressiveness to prevent overfitting and ensure a well-defined optimization. -
Generator
: The generator produces samples , where , and aims to minimize the discrepancy measured by the critic. In doing so, it adjusts its parameters so that the generated distribution becomes indistinguishable from the data distribution . When the minimax game reaches equilibrium, the generator has successfully learned to replicate the data distribution.
This adversarial structure underlies many modern generative models, including the Generative Adversarial Network (GAN), where the critic is typically implemented as a neural network, and the optimization alternates between updating
Classical GAN
The original GAN, proposed by Goodfellow et al. [@goodfellow2020generative], can be viewed as a special case of the IPM framework with an implicit convex regularizer defined by
where the convex function
With this choice, the GAN loss becomes
where
Here,
More generally,
Wasserstein GAN
The Wasserstein GAN [@arjovsky2017wasserstein] reformulates GAN training as minimizing the Wasserstein distance between the data and model distributions. This distance arises naturally from the integral probability metric (IPM) framework when the critic
where the Lipschitz norm is defined as
Practical Implementation
In practice, the Lipschitz constraint is enforced approximately by constraining the parameters of the critic
where
WGAN-GP
Weight clipping can restrict the critic’s capacity and lead to optimization issues. To address this, the improved WGAN by [@gulrajani2017improved] replaces the hard constraint with a gradient penalty (GP) that softly enforces the Lipschitz condition:
where
and
Here,
The gradient penalty encourages the critic to have gradients of unit norm along the straight line between real and generated samples.
Remark 4.2.It is reasonable to use the following variance of gradient penalty:
which places penalty only when the gradient magnitude is larger than one, i.e.,
.
Solving Minimax with Alternating Gradient Descent
In general, GAN training can be formulated as solving a minimax optimization problem:
where
is the adversarial loss functional that couples the generator
In practice, GANs are trained by alternating gradient descent, that is, by repeatedly updating the critic and the generator in turn using gradient-based optimization. A typical training iteration alternates between:
-
Critic update: Maximize
with respect to (often for several steps) while holding fixed. -
Generator update: Minimize
with respect to using the most recent critic.
See the algorithm below for an illustration of this alternating update procedure.
Update critic parameters
Update generator parameters:
Remark 4.3.Although the regularization term
may depend indirectly on the generator through the generated data (for example, in WGAN-GP where depends on ), it is common practice to stop the gradient through when updating the generator. That is, we treat as a fixed quantity that does not backpropagate into the generator parameters .
A practical implementation of the improved WGAN algorithm is summarized below:
Given: dataset
Update critic
Sample noise